Most enterprise AI failures begin before the model ever sees the data.
A few weeks ago someone implementing AI at a large institution walked me through a problem. The setup is one most people will recognise. Hundreds of thousands of applications arrive every month. The supporting paperwork is scanned, often handwritten in places, frequently in Hindi or another Indian language. Verification today is manual. Slow and expensive.
The brief on paper looks straightforward. Use an AI to read the documents, pull out the key fields, flag the ones that don’t match. The pitches he was hearing were confident. The demos were clean.
I pulled out my phone and showed him two screenshots.
The test
The document I had used was a real one. A Hindi government letter from late 2023 about stalled real estate projects in Noida. Eight pages, mostly typed, with a few handwritten fields at the top. One of those handwritten fields is the document’s reference number.
The reference number is the primary key. Get the body of a translation a bit wrong and you have fuzzy notes. Get the reference number wrong and you have just pulled the wrong file from the wrong cabinet. Every downstream step is now about a different record.
I had uploaded the PDF to a frontier chatbot. The kind of place a company would default to if it wanted “AI” without thinking too hard. Asked it to translate the page.
It produced clean, fluent English. Most of the body was fine. The header came out as:
Document Reference: संख्या-ननण4(1)/77-4-2023-6011/2023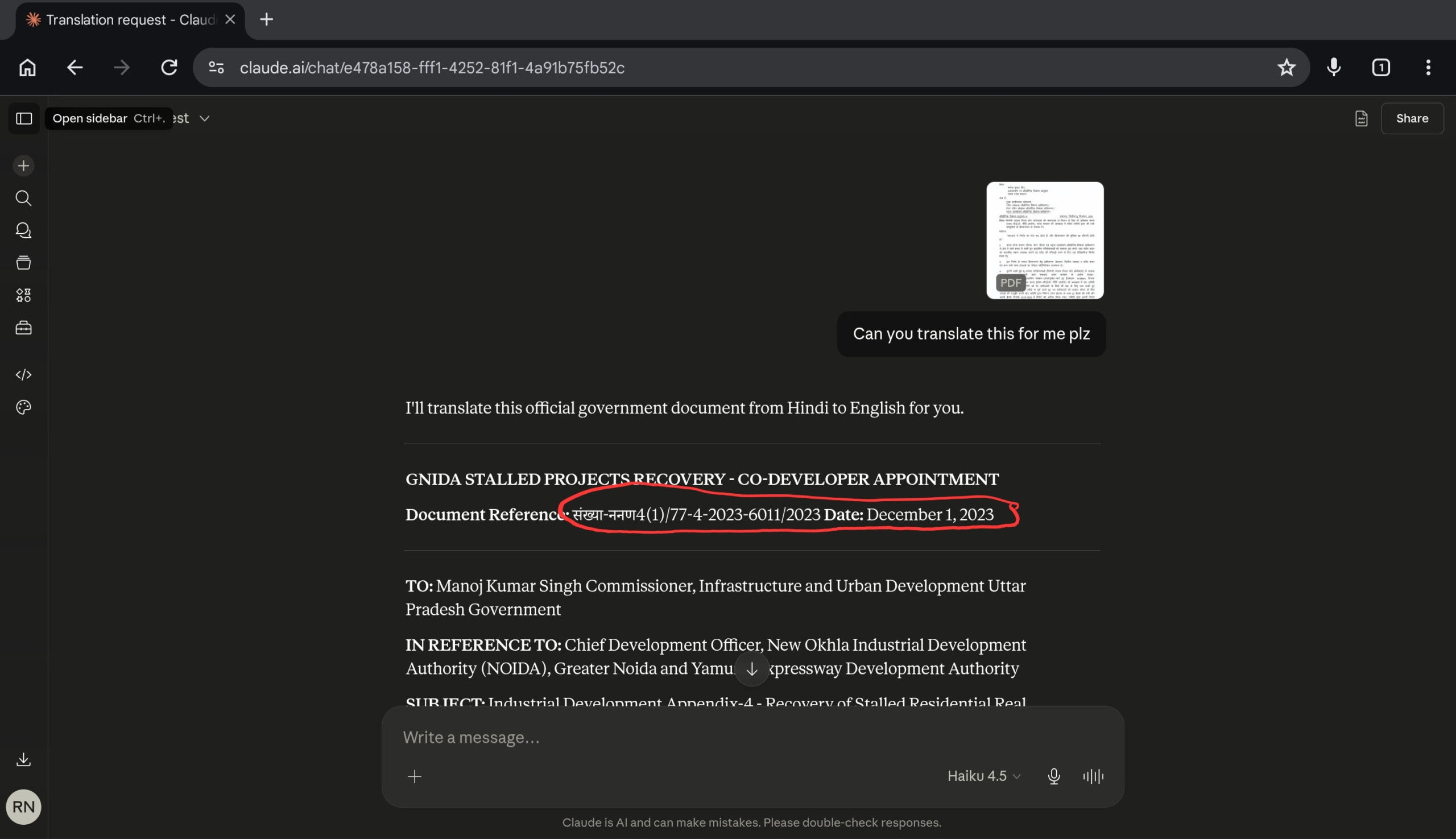
Two problems on a single line. It left the Hindi word “संख्या” untranslated (it just means “Number”). And the handwritten digits “7774” came out as “ननण4(1)” — gibberish Devanagari characters that happen to be roughly the same shape as the pen strokes on the page. The model did what models do. It produced a plausible-looking output for an input it could not actually read.
The garbage just looks polished now.
The other screenshot
Same letter, this time run through a specialised pipeline built for Indian documents. Smaller model. No frontier API.
No.7774/77-4-2023-6011/2023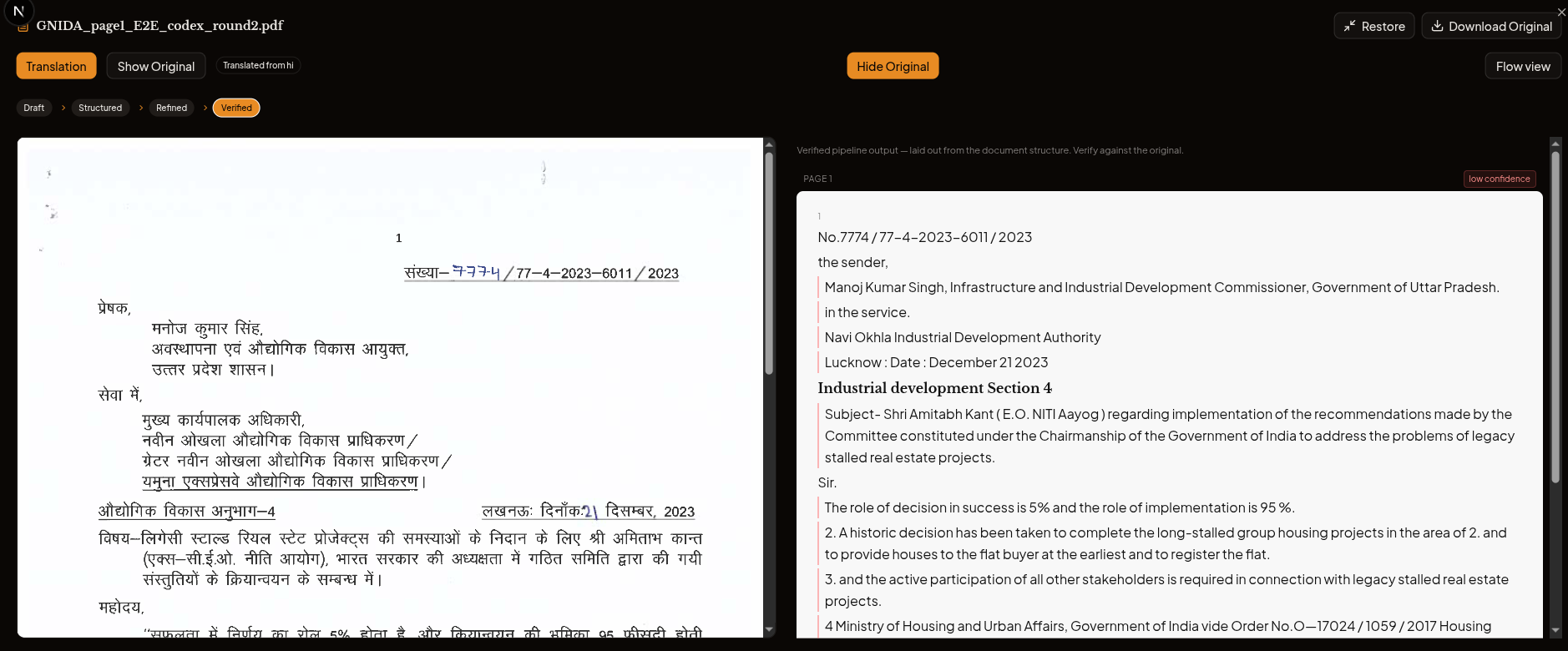
Right number. Right English field name. It read the handwriting.
Forget which screenshot won. The interesting work was happening somewhere else entirely. The frontier chatbot is a generalist model being asked to look at raw pixels of an unfamiliar form. The other setup has a specialised retrieval and preprocessing layer running before the model ever sees the page. Something that knows what a state government letterhead looks like, knows the difference between Devanagari letters and Devanagari numerals, knows where the reference field sits. The model gets a clean input. So it gives a clean answer.
Retrieval quality matters more than model sophistication. That is the lesson of every serious deployment I have seen on real Indian documents, and it is the part most “AI strategy” decks skip over because it doesn’t make for a sexy slide.
The frontier model wasn’t bad. It wasn’t built for the input it was being handed. And no amount of prompt engineering on top of it will fix that. With the right input, a 7B model gets it right. Often a 3B will do.
Why “Human in the loop” won’t save you
The standard answer when someone shows you a failure like this is: fine, we will put a human reviewer in the loop. It sounds responsible. On this particular failure mode, it does almost nothing — and it doesn’t actually reduce anyone’s workload either.
Look at the two outputs again. The wrong one is plausible. Same length. Same separators. Same year suffix. A reviewer skimming a hundred applications a day will trust it. The reviewer’s job quietly becomes rubber-stamping fluent output, which is not review at all. The mismatch surfaces months later. A loan disbursed to the wrong vendor. A board paper that quoted the wrong file all along. A recovery notice fired off against the wrong counterparty, with all the legal exposure that carries. By the time anyone notices, the trail is cold and the cleanup belongs to someone else’s quarter.
Now picture the same pipeline feeding into something that matters more. A board note, drawn from twenty source documents. The AI pulls out the figures, names, dates, references. It gets a few key fields wrong, plausibly, in the same fluent register as the rest. The employee whose name is going on the cover page now has to verify every line in the note against twenty original documents. That is more work than writing the note from scratch, not less. The AI didn’t reduce the human’s job. It shifted it from drafting to forensic checking, and forensic checking is the harder job.
HITL works when the AI’s failures look wrong. It doesn’t work when the AI’s failures look polished.
What guardrails actually mean
When people in the AI delivery business say “guardrails,” they often mean a list of don’ts in a system prompt and a confidence score on the output. That is not what guardrails look like in production for this kind of work.
This applies anywhere the inputs are real-world paperwork. KYC at a bank. Claims at an insurer. Vendor onboarding at a manufacturer. Contracts review at a law firm. Welfare applications at a government desk. The guardrails that actually work look like this.
A retrieval and pre-processing layer designed for the specific document type. Language, script, layout, handwriting handling. The model never sees raw pixels with a generic instruction.
A schema-bound extraction step. The output is not free text. It is a structured object with named fields and validation rules. “Reference number must match this regex” is a guardrail. “Try to be accurate” is not.
A cross-check against a known register. The extracted reference number is looked up against the actual file system before anything is processed. No match, no auto-process.
A refuse-rather-than-guess threshold. When the underlying confidence on a field is below a defined line, the system kicks that specific cell back to a human with the question highlighted. Not the whole document. The cell.
None of this is novel research. It is engineering discipline. It is also the part of the project that gets cut when someone wants a demo by Friday.
So what
If you are building an AI feature anywhere the inputs aren’t already clean — a bank, an insurer, a manufacturer, a law firm, a government scheme — the first thing to build is not the model integration. It is the data fetch and the schema. The first rupee should not go to the LLM bill. It should go to the pipeline that decides what ever reaches the LLM.
A frontier model fed the right input will give you the right answer. The same model fed a raw scanned Hindi PDF and a hopeful prompt will give you a wrong answer that looks correct. With one hundred percent confidence. Every time.
Garbage In, Garbage Out is the same problem it has always been.
The danger is no longer bad output.
The danger is bad output that looks trustworthy.