Most enterprise AI conversations begin with the same question: which model should we use?
This is the wrong starting point.
In production systems the model is often the smallest component of the architecture. The real work lies in the layers around it — data retrieval, verification, change control, and auditability. Understanding those layers is the difference between an AI demo and an enterprise AI system.
And most organisations are building it in exactly the wrong order.
The Missing Middle
Here is what most enterprise AI deployments actually look like:
A team purchases cloud compute or sets up a GPU server. They connect a large language model. They build a chat interface or a simple workflow on top. Leadership sees the demo and approves the pilot.
In stack terms, the organisation has Layer 1 (infrastructure) and Layer 6 (an application). Layers 2 through 5 are empty.
Those four missing layers — the Missing Middle — are where every production AI system succeeds or fails. And most organisations do not know they exist until the pilot stalls at 60 days.
The 6-Layer Enterprise AI Model
The enterprise AI architecture can be understood as six layers, built from the bottom up. I call this the 6-Layer Enterprise AI Model.
The core principle is simple: AI capability without infrastructure is a demo. Infrastructure without AI capability is a foundation. Only one of those becomes a production system.
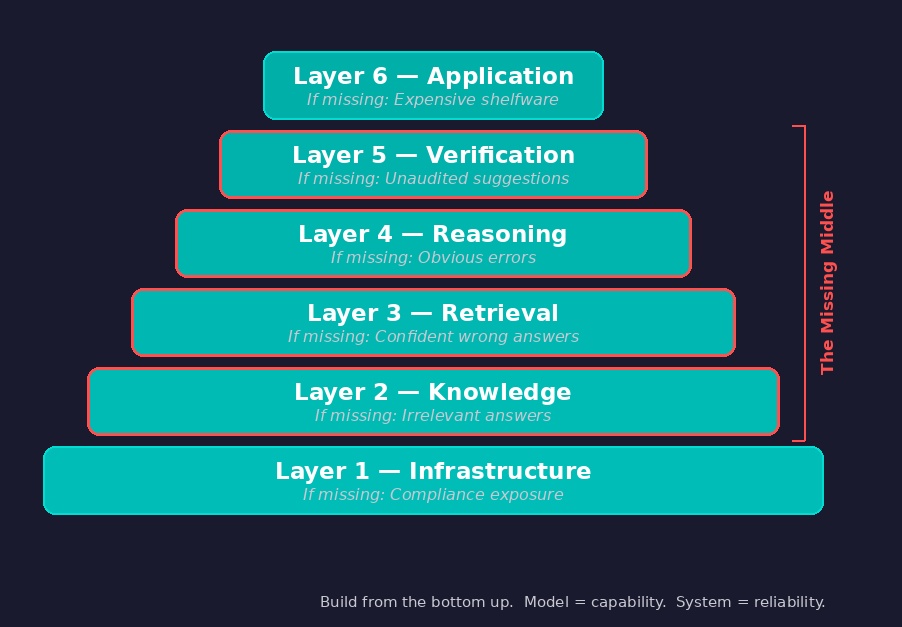
Layer 1 — Infrastructure
At the bottom of every enterprise AI system sits infrastructure: compute resources, model serving, document storage, and security boundaries.
In regulated industries — finance, healthcare, legal — this layer often runs on-premise because sensitive documents cannot leave the organisation. The infrastructure decision is not a technology question. It is a data governance question. Where does our data live, and who can access it?
Readiness signal: You can answer, in one sentence, where your AI system’s data is stored and who has access to it. If this requires a meeting to determine, the layer is not ready.
Layer 2 — Knowledge Layer
AI systems rarely reason directly over raw documents. They rely on structured representations — embeddings, indexed knowledge stores, structured metadata — that determine what information the system can retrieve.
This is the layer most teams underestimate. A model is only as good as what it can see. If your documents are unstructured PDFs in a shared drive, the model is working with fragments. Building the knowledge layer means converting organisational knowledge into a form the system can actually search.
Readiness signal: When someone asks the system a question, it retrieves the right source documents — not just documents that contain the right keywords, but documents that contain the right answer. If retrieval is unreliable, nothing above this layer will work.
Layer 3 — Retrieval Layer
Once knowledge is indexed, the system must decide which information to pass to the model. This is the retrieval layer — responsible for ranking, filtering, and extracting the right context from potentially thousands of documents.
Retrieval is not search. Search returns a list of documents. Retrieval selects the specific passages the model needs to answer a particular question in a particular context. The difference in quality between a naive keyword search and a well-designed retrieval pipeline is the difference between a system that hallucinates and one that does not.
Readiness signal: The system consistently surfaces the correct source material for a given query, even when the answer spans multiple documents or requires understanding document structure rather than just keywords.
Layer 4 — Reasoning Layer
Only after the previous three layers does the language model enter the pipeline.
This is the layer that gets all the attention. GPT-4, Claude, Llama — the model selection conversation dominates most AI strategy discussions. But in a well-designed stack, the model is a component, not the system. It performs a specific task — summarisation, comparison, rewriting, classification — using the context provided by the lay
_ers below it.
The strategic implication is counterintuitive: the choice of model matters far less than the quality of what you feed it. A smaller model with excellent retrieval will outperform a larger model with poor retrieval, every time.
Readiness signal: You can swap the model and the system still works. If changing the model breaks everything, the system is too dependent on the reasoning layer and not enough on the layers below it.
Layer 5 — Verification Layer
This is the layer most enterprise AI architectures skip entirely. And it is the reason most of them fail.
Enterprise systems require mechanisms to validate whether outputs are correct, consistent with source data, and within acceptable confidence bounds. In finance, every number in a report must trace back to a source. In legal work, every clause must reference its origin. AI systems require the same discipline.
A model that is correct 85% of the time still requires a human to verify 100% of its outputs — because the 15% that is wrong is indistinguishable from the 85% that is right. The verification layer is the infrastructure that makes this manageable: confidence scoring, source attribution, automated cross-checks, and audit trails.
Without this layer, AI outputs are unaudited suggestions. With it, they become governed system outputs.
Readiness signal: When the system produces an output, a non-technical reviewer can trace exactly how that output was generated — what sources were used, what reasoning was applied, and where the system’s confidence is low. If the output is a black box, this layer is missing.
Layer 6 — Application Layer
Finally the user interacts with the system through chat interfaces, dashboards, automated workflows, or integrated tools.
This is where most organisations begin their AI journey. It is the most visible layer and the easiest to build. It is also the least important. A beautiful interface on top of missing infrastructure is a demo. A reliable stack with a simple interface is a production system.
Readiness signal: Users trust the system enough to rely on it without manually checking every output. If users routinely override or ignore the system’s outputs, the problem is not the interface — it is one of the layers below.
When a Layer Is Missing
Every failure in an enterprise AI system traces to a specific missing layer:
| Missing Layer | What Fails | How It Looks |
|---|---|---|
| Infrastructure | Data leaves the building | Compliance exposure |
| Knowledge | System cannot find the right information | Irrelevant or incomplete answers |
| Retrieval | System finds wrong passages | Confident, well-written, wrong answers |
| Reasoning | Model cannot handle the task | Obvious errors, format failures |
| Verification | Nobody can check if the output is right | Unaudited suggestions treated as facts |
| Application | Users do not trust or use the system | Expensive shelfware |
“But What If the Model Just Gets It Right?”
This is the most common challenge to the 6-Layer Enterprise AI Model. If a powerful enough frontier model can produce correct outputs without structured retrieval or verification, why invest in the other layers?
Model equals capability. System equals reliability. They are not the same thing.
Sometimes the model does get it right. But it is not reasoning from your data — it is pattern-matching from its training corpus. If the training data happened to contain similar information, the output may look correct. But it will not reflect your latest agreements, your specific terms, or your current context. The next question — slightly different, slightly more specific — will expose the gap.
A powerful model can occasionally bridge the Missing Middle. But bridging is not building. An output that cannot be traced to your source data is not a reliable enterprise output. It is a pattern match that happened to land.
Where This Applies Most
The 6-Layer Enterprise AI Model applies across industries, but the layers that matter most shift by context. In regulated industries — finance, legal, healthcare — Layers 1 and 5 dominate, because data sovereignty and verification are non-negotiable. In knowledge-intensive organisations, Layers 2 and 3 dominate, because the quality of knowledge structure and retrieval determines everything. In consumer-facing applications, Layers 4 and 6 matter most, because model quality and user experience drive adoption. The framework is the same. The weight shifts.
The Build Order
The critical insight of the 6-Layer Enterprise AI Model is the build order. Most organisations build from the top down: interface first, then model, then maybe retrieval. The layers that matter most — knowledge, retrieval, and verification — are treated as afterthoughts.
The organisations that succeed build from the bottom up:
First, establish infrastructure and data governance (Layer 1). Then build the knowledge layer — clean, structured, indexed data (Layer 2). Then design retrieval so the system surfaces the right information (Layer 3). Only then select and integrate the model (Layer 4). Add verification and audit infrastructure (Layer 5). Finally, build the interface (Layer 6).
In operation, these layers interact — verification reveals retrieval gaps, usage exposes knowledge gaps. But the build order remains bottom-up. You cannot iterate on layers you never built.
This order feels slow. It is not. The demo costs less and ships faster. The production system costs more and takes longer. The organisations that choose the demo first end up paying for both.
The Diagnostic
If your organisation is considering or has already launched an AI initiative, the 6-Layer Enterprise AI Model provides a simple diagnostic. Ask one question per layer:
1. Infrastructure — Where does our data live and who controls access?
2. Knowledge — Is our organisational knowledge indexed in a form AI can search, or is it scattered across file shares and email?
3. Retrieval — When the system retrieves context for a query, does it consistently find the right source material?
4. Reasoning — Are we evaluating models based on benchmarks, or based on how they perform with our actual data and retrieval pipeline?
5. Verification — Can a reviewer trace how any given output was produced? Is there an audit trail?
6. Application — Do users trust the system enough to use it without manually checking every result?
Most organisations will find they can answer questions 1 and 6. The questions in between — the Missing Middle — are where the work is.
Who Owns Each Layer?
In most organisations, nobody does. Infrastructure is IT. The model is the data science team. The application is product. Layers 2, 3, and 5 — knowledge, retrieval, and verification — sit in a gap between departments, owned by none of them.
This is why they do not get built. Not because the technology is hard, but because the organisational design does not account for them. Someone must own the integrity of the full stack — not just a layer. That is not a technical role. It is a leadership role.
The Strategic Implication
When organisations say AI does not work, the problem is rarely the model. More often the system is missing one of the middle layers: knowledge infrastructure, retrieval design, or verification.
The model is the part that costs the least, changes the fastest, and matters the least to production reliability. The layers around it are the part that takes the longest to build, is hardest to retrofit, and determines whether the system actually works.
The organisations that understand this will not merely experiment with AI. They will operationalise it.