Most companies experimenting with AI are sending sensitive data to external APIs.
Contracts. Financial models. Board resolutions. Investor reports.
That works — until it doesn’t.
In regulated industries, the constraint is not model capability. It is data control.
Which is why I ended up building a private RAG system on my home server — as a way to understand what enterprise-grade AI actually requires when data cannot leave the building.
The Problem
Document-intensive industries run on paper. Agreements, term sheets, title records, regulatory filings — thousands of pages per deal, decades of institutional knowledge locked inside Word documents and scanned PDFs.
People waste hours searching for specific clauses, cross-referencing terms across documents, and answering the same questions repeatedly.
Cloud AI tools appear to solve this. Upload a document, ask a question, get an answer.
But there is a fundamental limitation: you can only upload one document at a time. You need to already know which document contains the answer. Was the revenue share defined in the main agreement or the side letter? Was there an amendment in a subsequent email exchange with the counterparty? Did the board resolution modify the original terms?
The system is not searching your knowledge. You are.
And even if retrieval were solved, there is a governance problem. Every document you upload leaves your control.
The Constraint
These documents contain the most sensitive information an organisation possesses — ownership details, commercial terms, strategic decisions, financial projections.
Sending any of this to an external API creates a data governance exposure that most regulated environments cannot accept. This is not paranoia. It is fiduciary responsibility. When you manage institutional capital, you do not get to hope that a third party handles your data responsibly. You need certainty.
The question becomes: can you get the benefits of AI-powered document intelligence without any data leaving your control?
Two Architectures
The difference between public and private AI is not the model. It is the data flow.
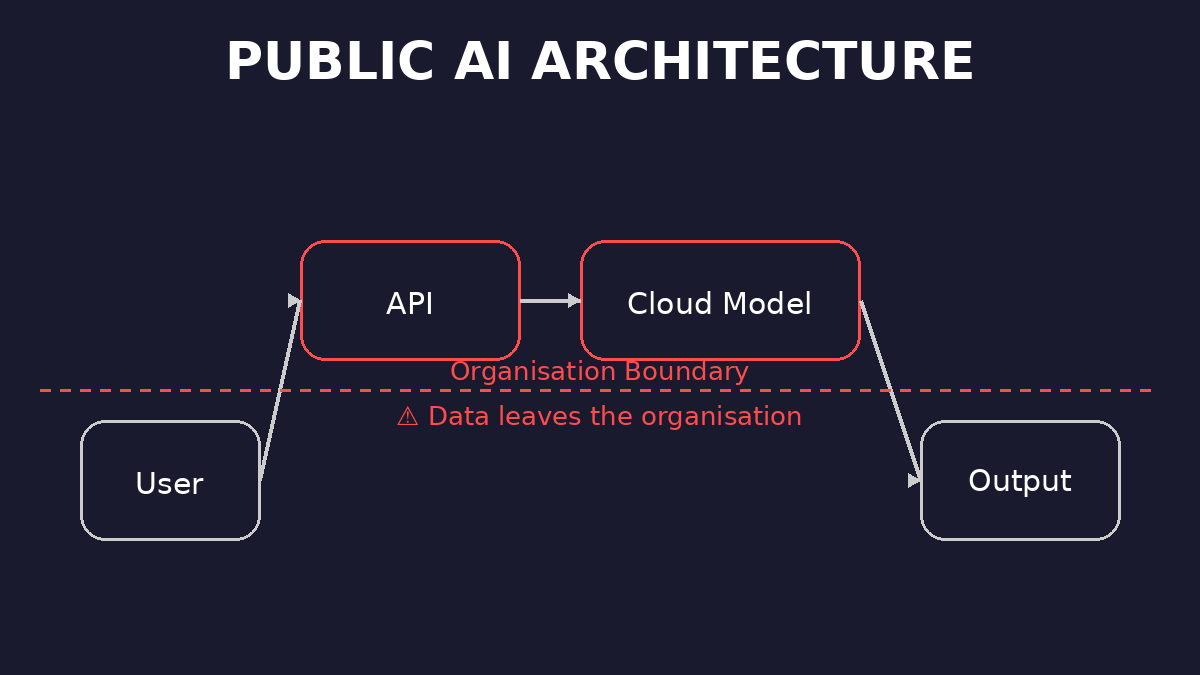
In a public AI architecture, the path is: user sends query and documents to an external API, a cloud model processes them, and output comes back. The data has left the organisation. You are trusting someone else’s infrastructure, someone else’s logging, someone else’s retention policy.
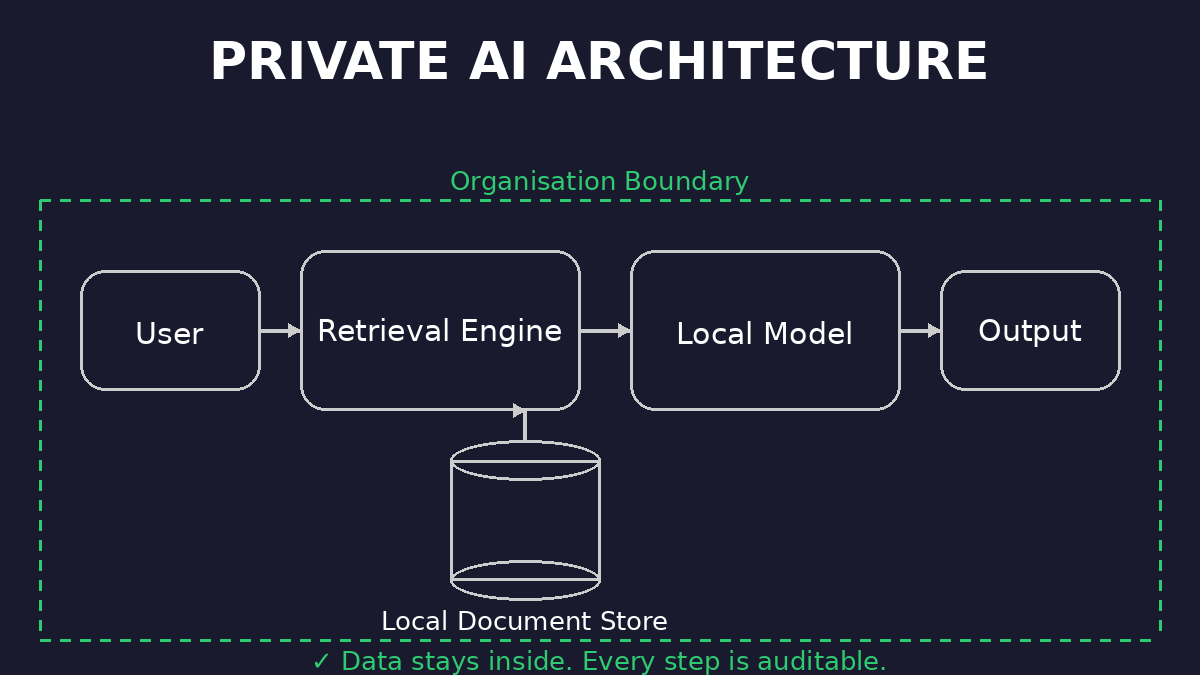
In a private AI architecture, the path is: user sends a query to a local retrieval engine, relevant passages are pulled from a local document store, a local model generates the answer. The data never leaves. Every step is auditable.
In the first architecture, you gain capability but lose control. In the second, you keep both.
The System
A private RAG system — Retrieval Augmented Generation — keeps the entire pipeline on local infrastructure. I built one on my home server to understand what this looks like in practice.
Ingestion: documents are parsed, chunked into meaningful passages, and converted into embeddings — numerical representations that capture semantic meaning. All on local hardware.
Retrieval: when a question is asked, the system searches across all ingested documents simultaneously — not through keyword matching, but through semantic similarity. A query about a revenue sharing arrangement matches passages about profit distribution mechanisms because the system understands they describe the same concept. Unlike cloud tools, there is no need to know which document to upload. The system searches everything.
Generation: a locally running language model reads the retrieved passages and produces an answer — with citations pointing back to specific documents and paragraphs. Every claim is verifiable against the source.
No data leaves the server. No API calls to external services. The model runs on local hardware. The documents stay where they are.
I run this on a Gentoo Linux server — an AMD Ryzen 7 8700G with sixty-four gigabytes of RAM. I compile llama.cpp from source with ROCm support to run inference on the integrated GPU, using GTT memory to access the full system RAM for model loading. The open-source stack — llama.cpp, sentence-transformers, FAISS — provides remarkable capability at zero licensing cost. The total hardware cost for this system is less than one month’s subscription to an enterprise cloud AI platform.
What This Revealed
Building the system taught me things that no vendor demo or benchmark paper would have.
Retrieval matters more than generation. If the system retrieves the wrong passages, even the best model produces a confident, well-written, completely wrong answer. I spent more time tuning retrieval — chunk sizes, overlap strategies, embedding model selection — than on anything else. Most enterprise AI conversations focus on which model to use. The better question is what are you feeding it.
Document parsing is the real engineering challenge. Real-world documents are messy. Tables that span pages. Numbered clauses nested four levels deep. Defined terms that mean different things in different agreements. Getting clean, structured text out of a two-hundred-page legal document has nothing to do with machine learning and everything to do with patience and edge cases.
Trust is the adoption bottleneck. Even when the system works technically, people need to verify answers against source documents enough times to build confidence. They need the system to be wrong once — and handle it gracefully with clear source attribution — before they trust it to be right. No accuracy metric replaces that experience.
On-premise does not mean primitive. The perception that running AI locally means sacrificing quality is outdated. What local AI requires is architecture, not budget.
The Real Question
The decision to build a private RAG system was not driven by performance. It was driven by governance.
In enterprise AI, the question is not just what the model can do. It is where the data lives — and who controls it.
Organisations that answer this question early build AI systems that compliance teams approve, boards fund, and users actually trust. Organisations that ignore it build impressive demos that never reach production.
The best AI system is not the one with the highest benchmark score. It is the one the organisation trusts enough to use.